3.1 Cây đoạn (Segment Tree)
Cây đoạn (Segment Tree) là một cấu trúc dữ liệu dạng cây nhị phân (binary tree) do Jon Louis Bentley đề xuất vào năm 1977. Nó dùng để lưu trữ các đoạn/miền (interval/segment), và cho phép truy vấn nhanh các đoạn phủ một điểm nhất định.
Với một cây đoạn lưu trữ đoạn, độ phức tạp bộ nhớ (space complexity) là ; còn truy vấn có độ phức tạp , trong đó là số đoạn thỏa điều kiện. Cấu trúc cây đoạn cũng có thể mở rộng lên không gian nhiều chiều (higher-dimensional).
I. Cây đoạn là gì?
Lấy ví dụ cây đoạn một chiều (1D segment tree).
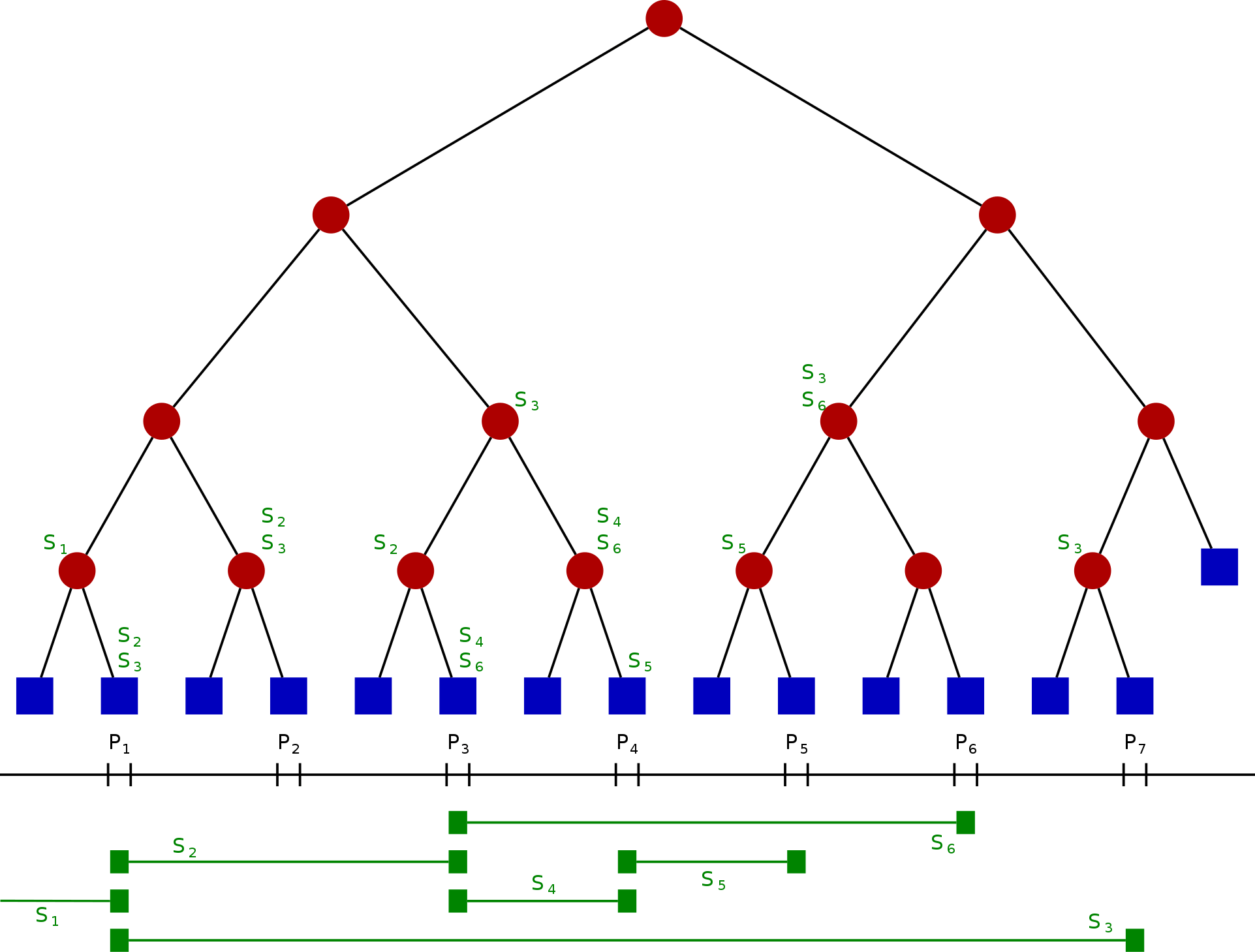
Gọi S là tập các đoạn thẳng một chiều. Sắp xếp các tọa độ đầu mút theo thứ tự tăng dần, ta được dãy . Mỗi khoảng sau khi bị các đầu mút này “cắt” ra được gọi là khoảng đơn vị (unit interval) — lưu ý: vị trí đúng tại mỗi đầu mút cũng được xem như một khoảng đơn vị riêng. Từ trái sang phải ta có:
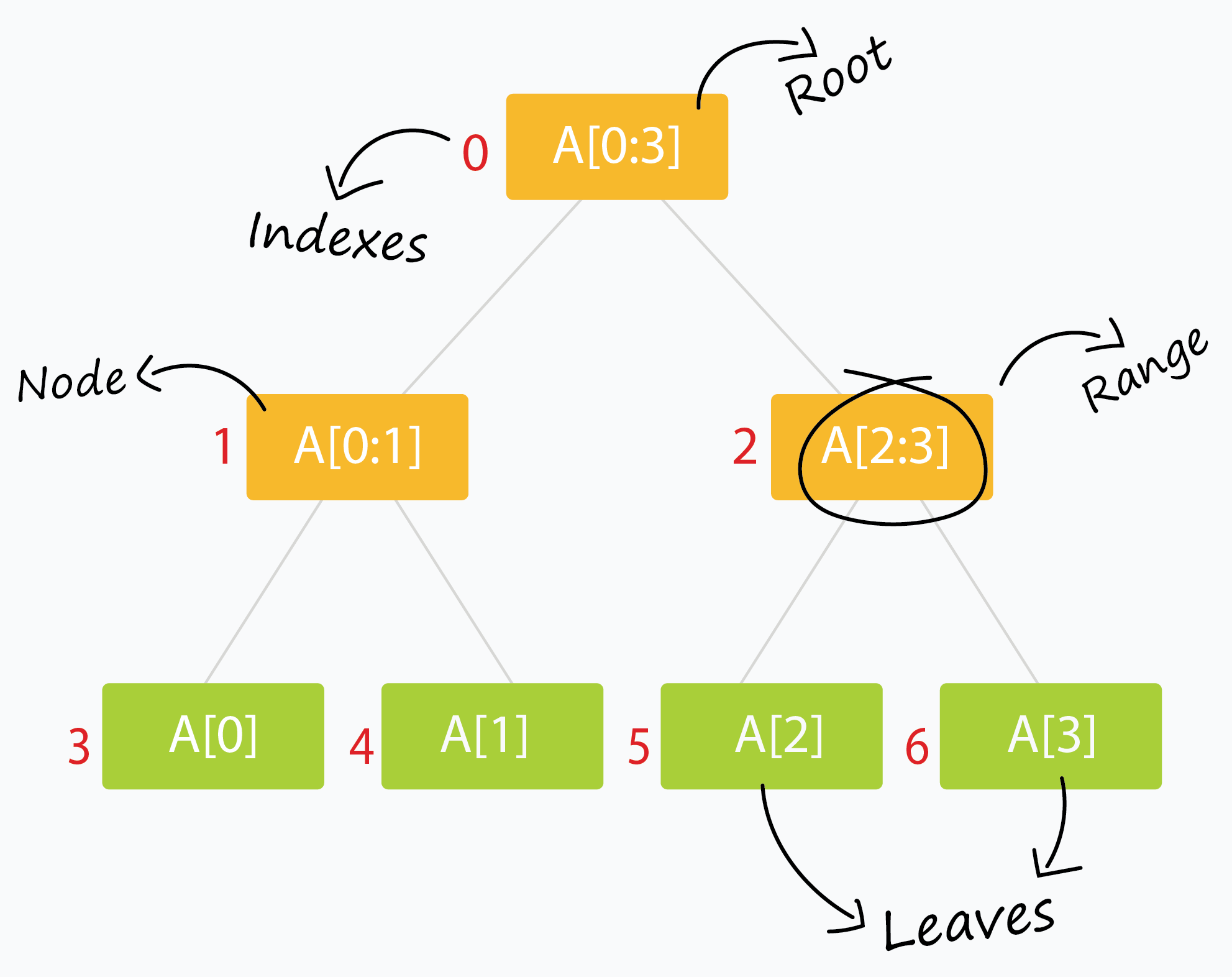
Cấu trúc cây đoạn là một cây nhị phân. Mỗi nốt biểu diễn một đoạn tọa độ; gọi đoạn của nốt N là Int(N). Cây đoạn thỏa các điều kiện:
- Mỗi nốt lá (leaf node), theo thứ tự từ trái qua phải, tương ứng với từng khoảng đơn vị (unit interval).
- Mỗi nốt trong (internal node) biểu diễn hợp (union) của hai đoạn con mà nó quản lý.
- Mỗi nốt (kể cả lá) có một cấu trúc để lưu các đoạn. Nếu một đoạn S bao phủ Int(N) nhưng không bao phủ Int(parent(N)) (tức là nốt cha của N), thì S sẽ được lưu tại nốt N.
Cây đoạn là một cây nhị phân mà mỗi nốt đại diện cho một khoảng. Thông thường, một nốt sẽ lưu thông tin tổng hợp của một hoặc nhiều khoảng con để phục vụ truy vấn.
II. Vì sao cần cấu trúc này?
Nhiều bài toán yêu cầu trả lời dựa trên truy vấn theo phạm vi/khoảng (range/interval queries). Nếu cứ quét tuyến tính thì sẽ bị chậm, đặc biệt khi số lượng truy vấn lớn và lặp lại nhiều lần. Cây đoạn cho phép xử lý những truy vấn này hiệu quả với độ phức tạp logarit.
Cây đoạn còn xuất hiện trong hình học tính toán (computational geometry) và hệ thống thông tin địa lý (Geographic Information Systems). Ví dụ, trong không gian có thể có rất nhiều điểm cách một điểm tham chiếu/gốc tọa độ một khoảng nào đó. Nếu ta cần tìm các điểm nằm trong một dải khoảng cách nhất định tới gốc, cách làm “thô” như dùng bảng tra cứu rồi quét tuyến tính qua tất cả điểm (hoặc tất cả khoảng cách, giả sử dùng bảng băm) sẽ rất tốn thời gian. Cây đoạn giúp truy vấn kiểu này trong thời gian logarit, trong khi bộ nhớ lại tương đối tiết kiệm. Những bài toán như vậy thuộc nhóm tìm kiếm theo miền (range searching). Việc giải hiệu quả rất quan trọng, nhất là khi dữ liệu động thay đổi liên tục (ví dụ: hệ thống radar điều phối không lưu). Phần dưới sẽ lấy ví dụ bài toán truy vấn tổng đoạn (Range Sum Query).
Hình trên minh hoạ cây đoạn dùng cho truy vấn theo phạm vi (range query).
III. Xây dựng cây đoạn (Segment Tree)
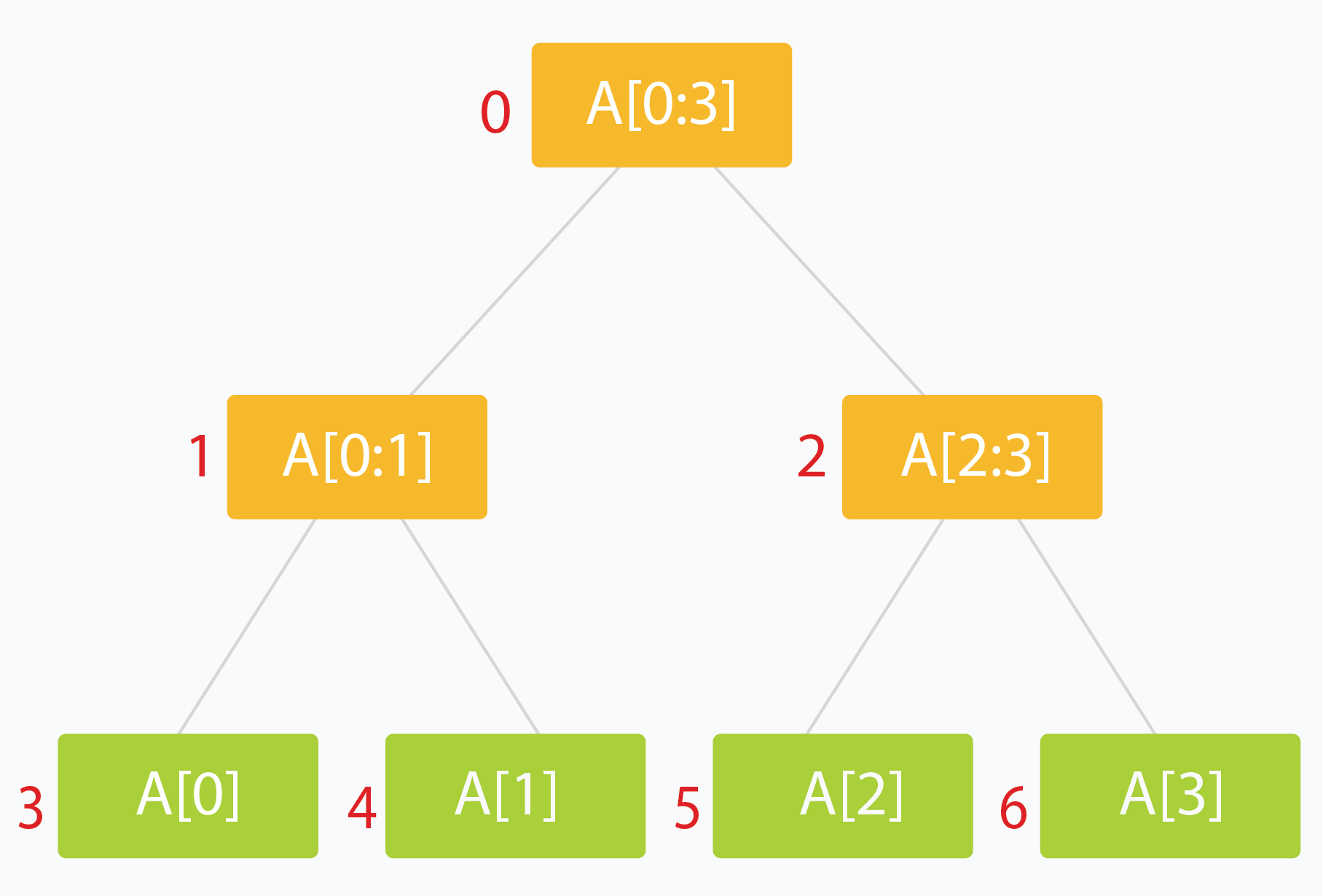
Giả sử dữ liệu nằm trong mảng arr[] có kích thước n.
- Nốt gốc (root) thường đại diện toàn bộ đoạn dữ liệu, ở đây là
arr[0:n-1]. - Mỗi lá (leaf) đại diện cho một đoạn chỉ có 1 phần tử:
arr[0],arr[1], …,arr[n-1]. - Nốt trong lưu kết quả tổng hợp từ hai nốt con.
- Mỗi nốt con thường quản lý “khoảng một nửa” của nốt cha (tư duy chia đôi / binary split).
Dùng một mảng kích thước khoảng là đủ để biểu diễn cây đoạn cho n phần tử. (Stack Overflow có giải thích hay; nếu bạn chưa rõ thì cứ yên tâm, đây là “mốc” thường dùng trong thực tế.)
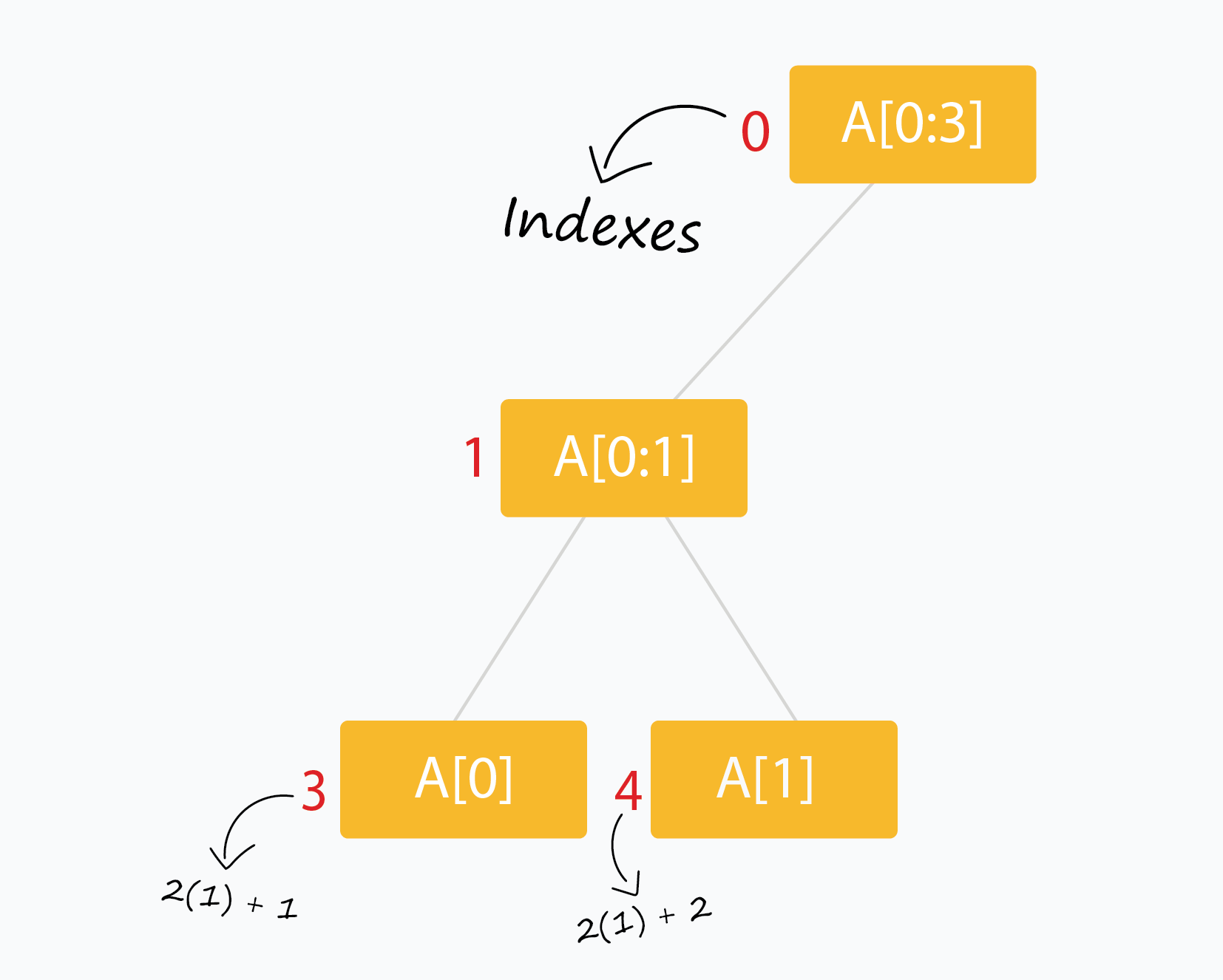
Với nốt ở chỉ số i, hai con của nó nằm ở và .
Cây đoạn khá trực quan và rất hợp để xây dựng bằng đệ quy (recursion).
Ta sẽ dùng mảng tree[] để lưu các nốt của cây đoạn (khởi tạo toàn 0). Chỉ số bắt đầu từ 0.
- Gốc ở
tree[0]. - Con của
tree[i]nằm ởtree[2*i+1]vàtree[2*i+2]. - Có thể “đệm” (pad) thêm
0hoặcnullvàoarr[]để làm cho (vớinlà tổng độ dài củaarr[],klà số nguyên không âm). - Chỉ số của các lá nằm trong khoảng .
Code xây dựng cây đoạn như sau:
// SegmentTree (cây đoạn / segment tree) - định nghĩa type SegmentTree struct { data, tree, lazy []int left, right int merge func(i, j int) int } // Init - khởi tạo func (st *SegmentTree) Init(nums []int, oper func(i, j int) int) { st.merge = oper data, tree, lazy := make([]int, len(nums)), make([]int, 4*len(nums)), make([]int, 4*len(nums)) for i := 0; i < len(nums); i++ { data[i] = nums[i] } st.data, st.tree, st.lazy = data, tree, lazy if len(nums) > 0 { st.buildSegmentTree(0, 0, len(nums)-1) } } // Tạo cây đoạn cho đoạn [left...right] tại vị trí treeIndex func (st *SegmentTree) buildSegmentTree(treeIndex, left, right int) { if left == right { st.tree[treeIndex] = st.data[left] return } midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) st.buildSegmentTree(leftTreeIndex, left, midTreeIndex) st.buildSegmentTree(rightTreeIndex, midTreeIndex+1, right) st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex]) } func (st *SegmentTree) leftChild(index int) int { return 2*index + 1 } func (st *SegmentTree) rightChild(index int) int { return 2*index + 2 }
Ở đây, tác giả đưa “phép gộp” (merge) thành một hàm. Tùy bài mà phép gộp sẽ khác nhau: cộng (sum), lấy lớn nhất (max), nhỏ nhất (min), v.v.
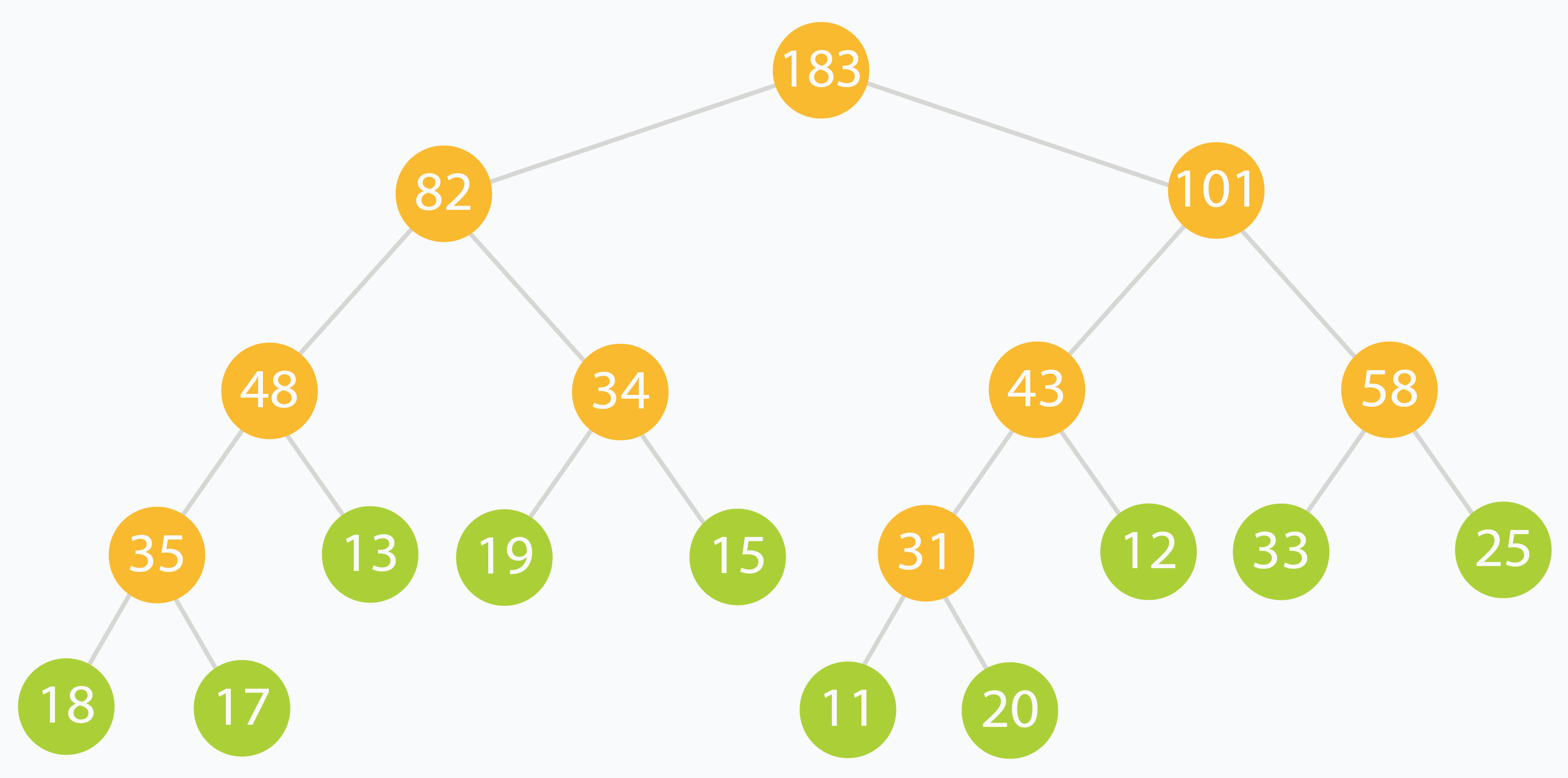
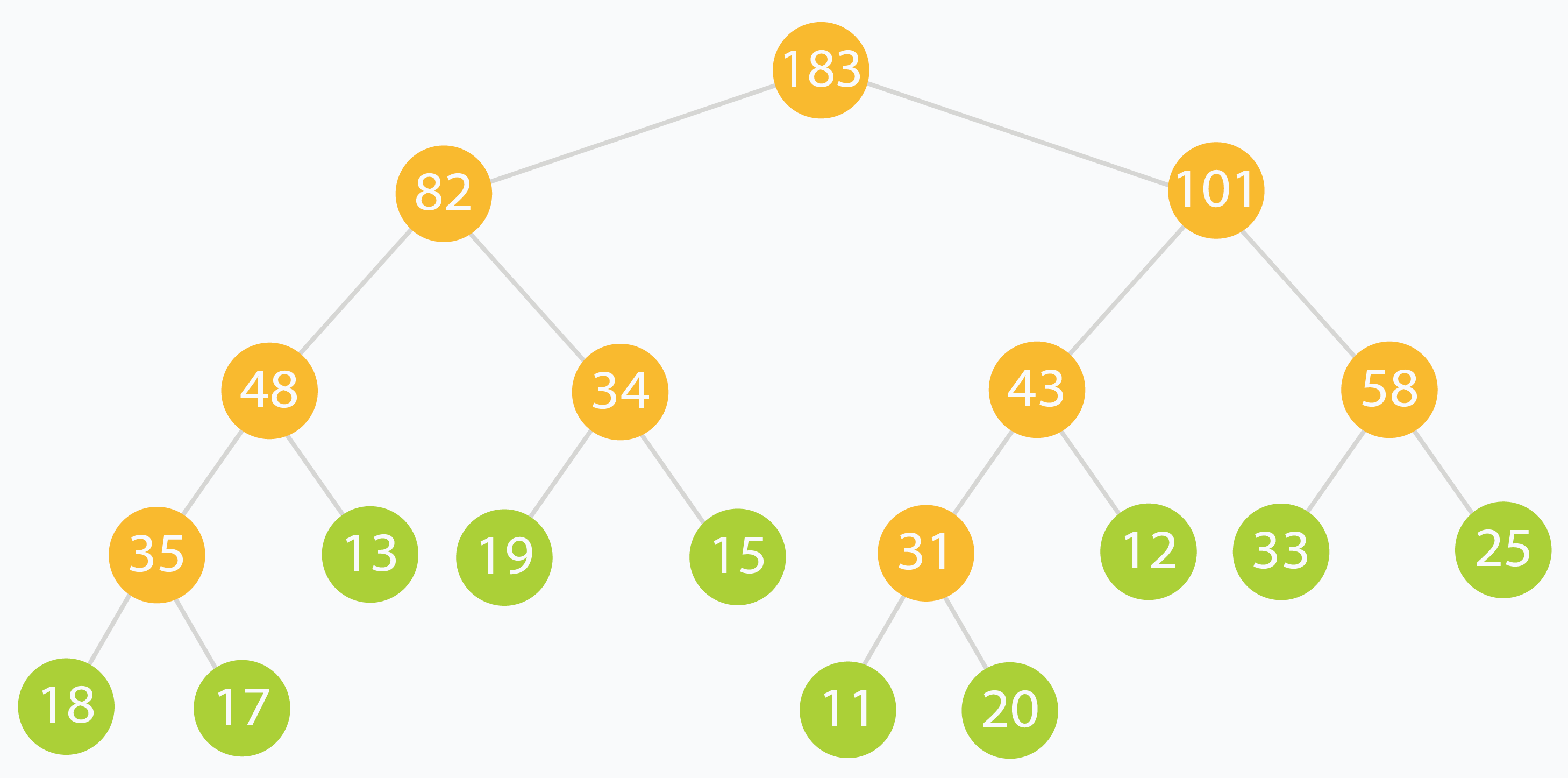
Ví dụ với arr[] = [18, 17, 13, 19, 15, 11, 20, 12, 33, 25], cây đoạn sẽ như sau:
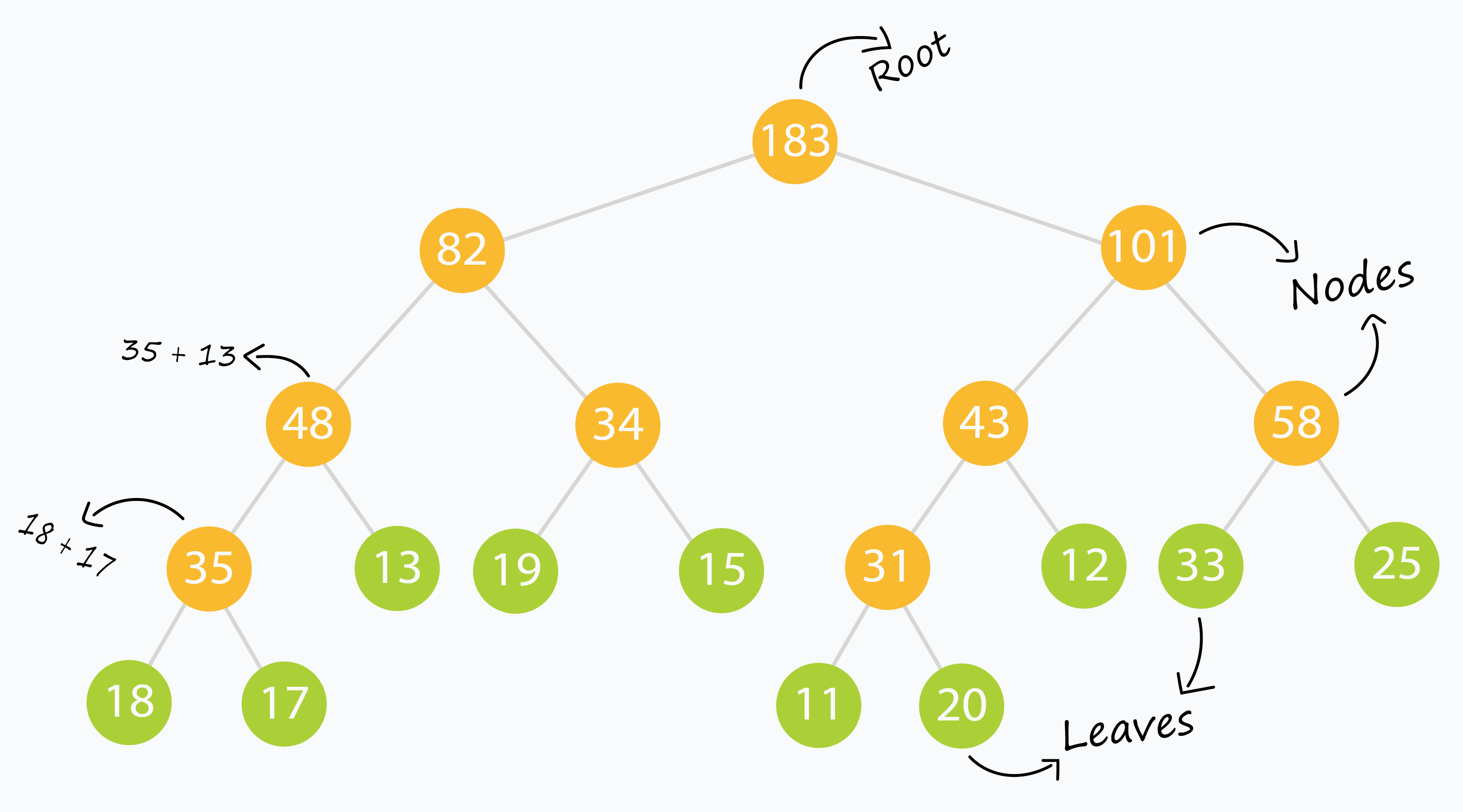
Sau khi xây dựng xong, mảng tree[] có thể trông như sau:
tree[] = [ 183, 82, 101, 48, 34, 43, 58, 35, 13, 19, 15, 31, 12, 33, 25, 18, 17, 0, 0, 0, 0, 0, 0, 11, 20, 0, 0, 0, 0, 0, 0 ]
Ta đệm 0 để mảng có đủ ~4*n phần tử.
Bài LeetCode liên quan: 218. The Skyline Problem、303. Range Sum Query - Immutable、307. Range Sum Query - Mutable、699. Falling Squares
IV. Truy vấn trên cây đoạn
Có hai cách truy vấn trên cây đoạn: truy vấn trực tiếp (direct query) và truy vấn lười (lazy query) — thường đi kèm với cập nhật lười (lazy update / lazy propagation).
1. Truy vấn trực tiếp (Direct Query)
Khi đoạn cần truy vấn khớp hoàn toàn với đoạn mà nốt hiện tại đại diện, ta trả về ngay kết quả tại nốt đó. Nếu không, ta đi sâu xuống các nốt con để tách truy vấn thành các phần khớp hoàn toàn.
// Truy vấn giá trị trên đoạn [left...right] // Query func (st *SegmentTree) Query(left, right int) int { if len(st.data) > 0 { return st.queryInTree(0, 0, len(st.data)-1, left, right) } return 0 } // Trong cây đoạn có gốc treeIndex (đang quản lý [left...right]), // truy vấn đoạn [queryLeft...queryRight] func (st *SegmentTree) queryInTree(treeIndex, left, right, queryLeft, queryRight int) int { if left == queryLeft && right == queryRight { return st.tree[treeIndex] } midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) if queryLeft > midTreeIndex { return st.queryInTree(rightTreeIndex, midTreeIndex+1, right, queryLeft, queryRight) } else if queryRight <= midTreeIndex { return st.queryInTree(leftTreeIndex, left, midTreeIndex, queryLeft, queryRight) } return st.merge(st.queryInTree(leftTreeIndex, left, midTreeIndex, queryLeft, midTreeIndex), st.queryInTree(rightTreeIndex, midTreeIndex+1, right, midTreeIndex+1, queryRight)) }
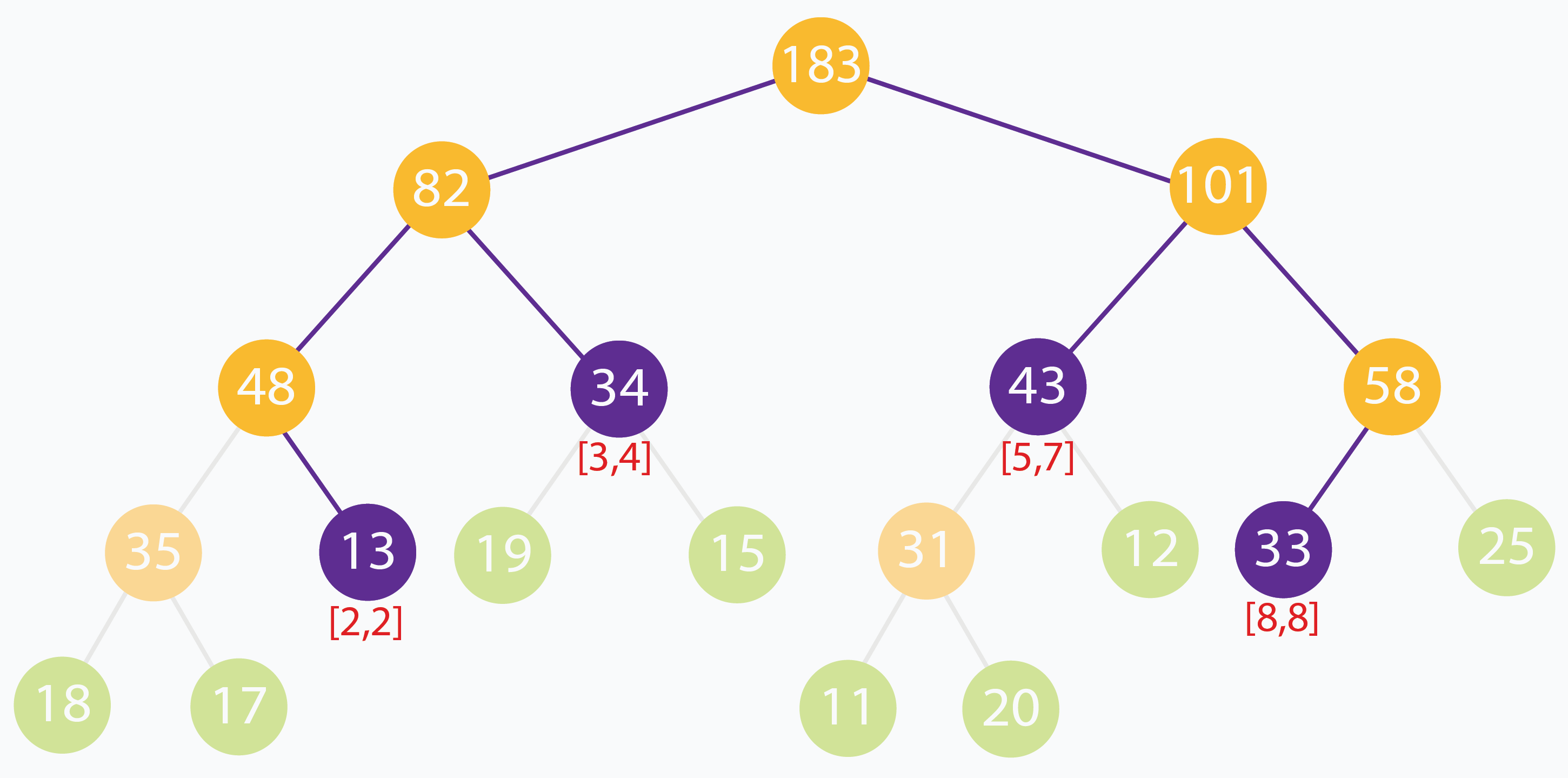
Trong ví dụ trên, ta truy vấn tổng các phần tử trong đoạn . Không có nốt nào biểu diễn đúng toàn bộ , nhưng ta có thể “ghép” từ các đoạn con khớp hoàn toàn: , , , . Kiểm tra nhanh: tổng giá trị là . Tổng ở các nốt tương ứng là . Kết quả đúng.
2. Truy vấn lười (Lazy Query)
Truy vấn lười đi kèm với cập nhật lười (lazy update / lazy propagation). Khi cập nhật một đoạn, ta không cập nhật ngay toàn bộ các nốt bên dưới, mà “ghi nợ” phần thay đổi vào mảng lazy[]. Tới khi truy vấn chạm vào nốt đó, ta mới “đẩy” (push) phần thay đổi xuống để đảm bảo thời gian truy vấn/cập nhật vẫn giữ ở mức , tránh xấu đi thành .
Các bước khi gặp một nốt “lười” (lazy node):
- Kiểm tra nốt hiện tại có “lười” không bằng
lazy[i] != 0. Nếu có, áp dụng phần cập nhật lên nốt hiện tại và cập nhật/lan xuống các con (giống hệt bước đầu của cập nhật lười). - Đệ quy xuống các nốt con để tìm các đoạn con phù hợp cho truy vấn.
Code minh hoạ:
// Truy vấn giá trị trên đoạn [left...right] // QueryLazy func (st *SegmentTree) QueryLazy(left, right int) int { if len(st.data) > 0 { return st.queryLazyInTree(0, 0, len(st.data)-1, left, right) } return 0 } func (st *SegmentTree) queryLazyInTree(treeIndex, left, right, queryLeft, queryRight int) int { midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) if left > queryRight || right < queryLeft { // segment completely outside range return 0 // represents a null node } if st.lazy[treeIndex] != 0 { // this node is lazy for i := 0; i < right-left+1; i++ { st.tree[treeIndex] = st.merge(st.tree[treeIndex], st.lazy[treeIndex]) // st.tree[treeIndex] += (right - left + 1) * st.lazy[treeIndex] // normalize current node by removing lazinesss } if left != right { // update lazy[] for children nodes st.lazy[leftTreeIndex] = st.merge(st.lazy[leftTreeIndex], st.lazy[treeIndex]) st.lazy[rightTreeIndex] = st.merge(st.lazy[rightTreeIndex], st.lazy[treeIndex]) // st.lazy[leftTreeIndex] += st.lazy[treeIndex] // st.lazy[rightTreeIndex] += st.lazy[treeIndex] } st.lazy[treeIndex] = 0 // current node processed. No longer lazy } if queryLeft <= left && queryRight >= right { // segment completely inside range return st.tree[treeIndex] } if queryLeft > midTreeIndex { return st.queryLazyInTree(rightTreeIndex, midTreeIndex+1, right, queryLeft, queryRight) } else if queryRight <= midTreeIndex { return st.queryLazyInTree(leftTreeIndex, left, midTreeIndex, queryLeft, queryRight) } // merge query results return st.merge(st.queryLazyInTree(leftTreeIndex, left, midTreeIndex, queryLeft, midTreeIndex), st.queryLazyInTree(rightTreeIndex, midTreeIndex+1, right, midTreeIndex+1, queryRight)) }
V. Cập nhật (Update) trên cây đoạn
1. Cập nhật một điểm (Point Update)
Cập nhật một điểm khá giống buildSegTree: ta cập nhật giá trị ở nốt lá tương ứng với phần tử được cập nhật, rồi “kéo” (pull) thay đổi lên các nốt tổ tiên cho tới gốc.
// Cập nhật giá trị tại vị trí index // Update func (st *SegmentTree) Update(index, val int) { if len(st.data) > 0 { st.updateInTree(0, 0, len(st.data)-1, index, val) } } // Với gốc treeIndex, cập nhật vị trí index thành val func (st *SegmentTree) updateInTree(treeIndex, left, right, index, val int) { if left == right { st.tree[treeIndex] = val return } midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) if index > midTreeIndex { st.updateInTree(rightTreeIndex, midTreeIndex+1, right, index, val) } else { st.updateInTree(leftTreeIndex, left, midTreeIndex, index, val) } st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex]) }
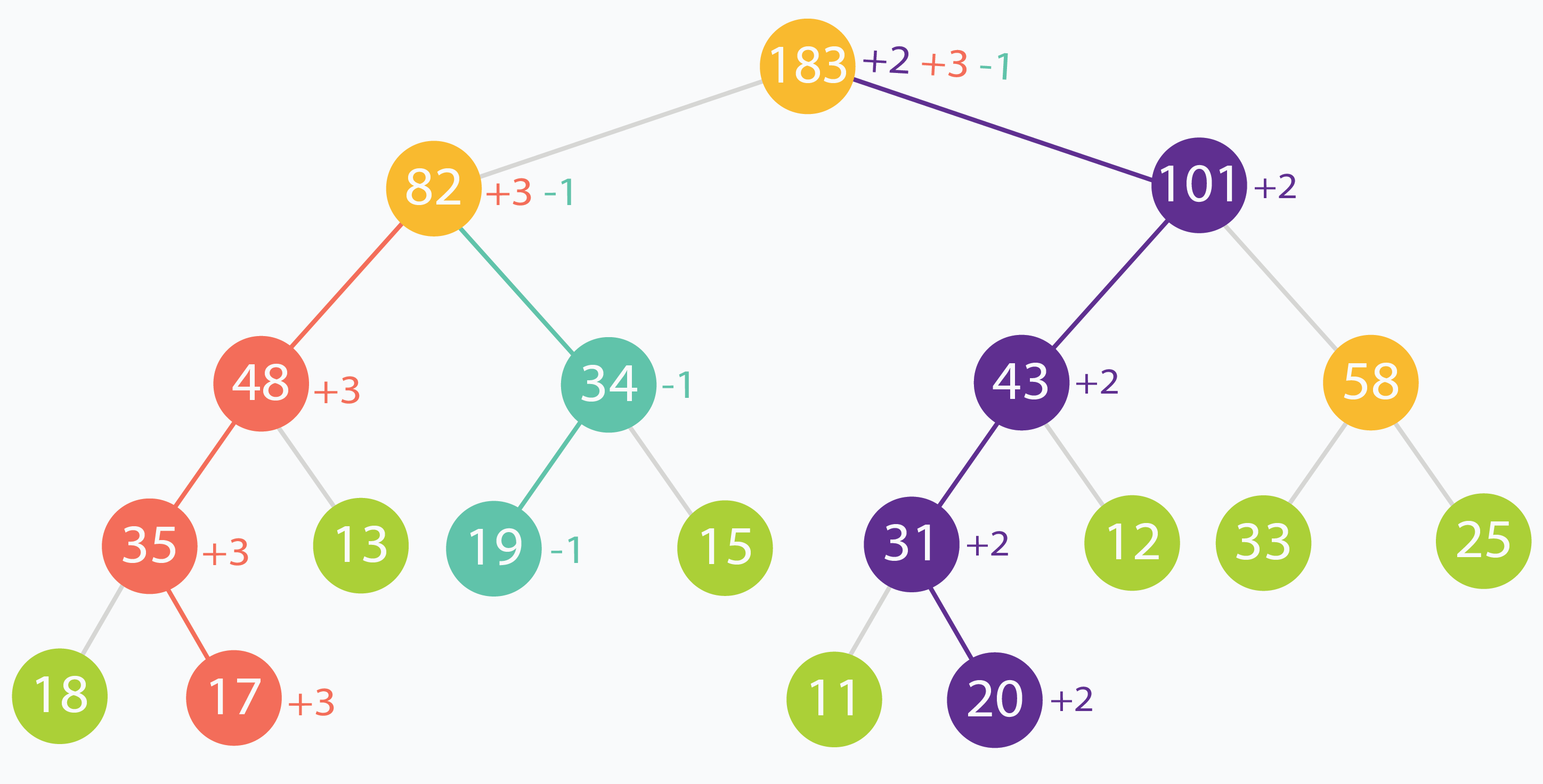
Trong ví dụ này, các phần tử ở chỉ số (trong dữ liệu gốc) 1, 3 và 6 lần lượt thay đổi +3, -1, +2. Bạn có thể thấy thay đổi được lan dần lên tới nốt gốc.
2. Cập nhật đoạn (Range Update)
Cây đoạn cập nhật một phần tử rất hiệu quả ( ). Nhưng nếu ta cần cập nhật cả một dải phần tử (một đoạn) thì sao? Nếu cập nhật từng phần tử độc lập, ta sẽ phải “đụng” đi đụng lại cùng một số nốt tổ tiên chung, gây lặp tính toán. Làm sao để tránh cập nhật trùng lặp đó?
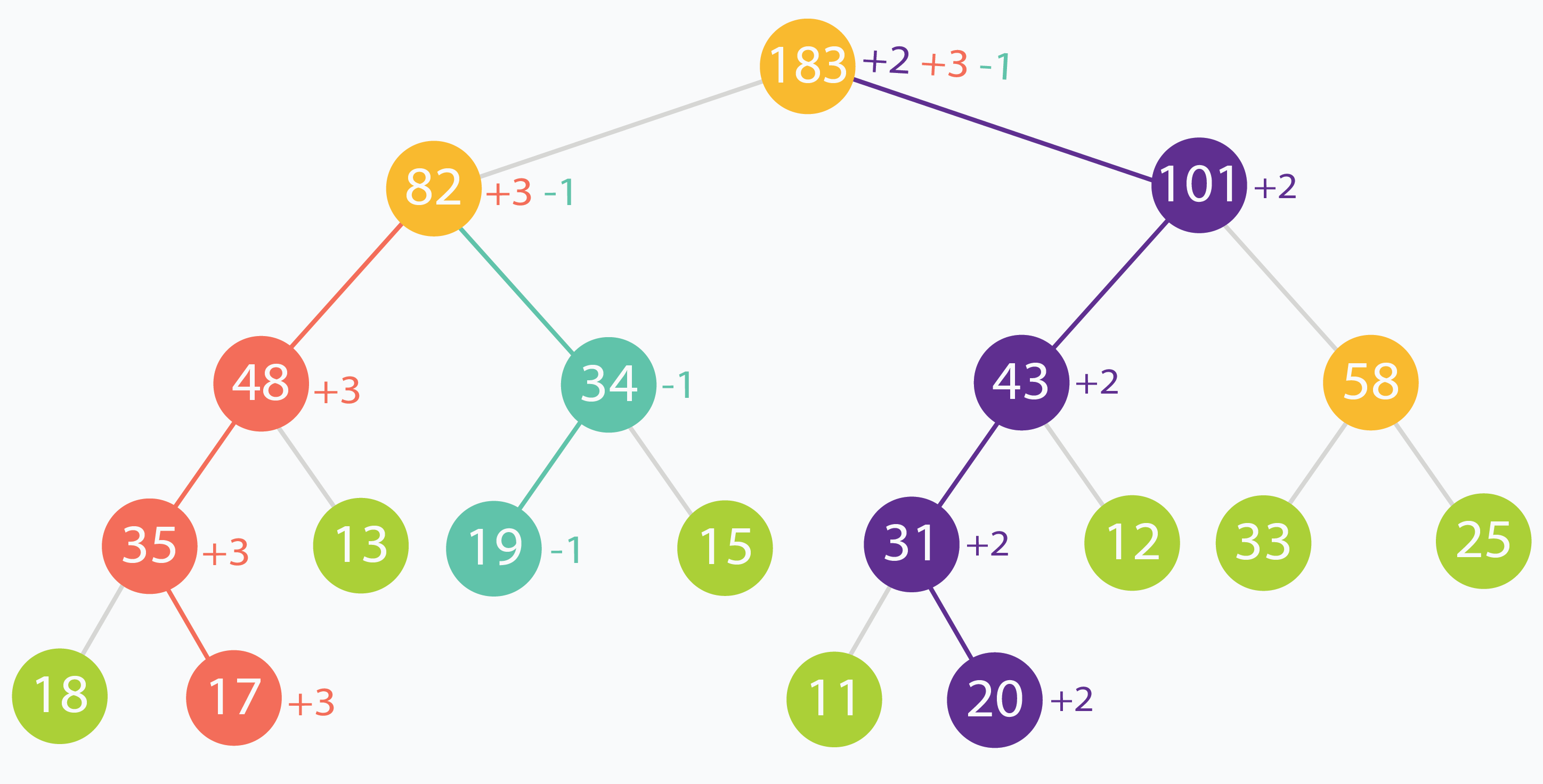
Trong ví dụ trên, nốt gốc bị cập nhật 3 lần và nốt có giá trị 82 bị cập nhật 2 lần, vì cập nhật lá sẽ ảnh hưởng lên các nốt phía trên. Trường hợp xấu hơn là: ta cập nhật nhiều nhưng lại ít khi truy vấn vào những vùng đó, dẫn tới tốn thời gian cập nhật những nốt “ít dùng”. Thêm mảng lazy[] giúp giảm tính toán không cần thiết và chỉ xử lý khi thực sự cần.
Ta dùng thêm mảng lazy[] cùng kích thước với tree[]. lazy[i] lưu “mức thay đổi còn nợ” cần áp dụng cho nốt tree[i] (tăng/giảm). Khi lazy[i] = 0, nghĩa là nốt không còn cập nhật treo nào.
Các bước cập nhật đoạn (range update):
- Nếu nốt hiện tại là nốt lười (
lazy[i] != 0), hãy áp dụng cập nhật lên nốt đó và đẩy phần lười xuống các con. - Nếu đoạn của nốt nằm hoàn toàn trong đoạn cần cập nhật, áp dụng cập nhật lên nốt và ghi
lazycho các con (nếu cần). - Ngược lại, đệ quy xuống các con, rồi gộp (merge) lại lên nốt hiện tại.
Code minh hoạ:
// Cập nhật đoạn [updateLeft...updateRight] // Lưu ý: cập nhật ở đây là cộng/trừ so với giá trị hiện tại, không phải gán cả đoạn thành x. // Cập nhật đoạn (range update) tập trung vào "độ thay đổi" (delta), còn cập nhật điểm (point update) thường là gán giá trị cụ thể. // Nếu muốn cập nhật đoạn theo kiểu gán giá trị cố định, thì chiến lược lazy và merge sẽ phải thay đổi; phần này tạm không bàn sâu. // UpdateLazy func (st *SegmentTree) UpdateLazy(updateLeft, updateRight, val int) { if len(st.data) > 0 { st.updateLazyInTree(0, 0, len(st.data)-1, updateLeft, updateRight, val) } } func (st *SegmentTree) updateLazyInTree(treeIndex, left, right, updateLeft, updateRight, val int) { midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) if st.lazy[treeIndex] != 0 { // this node is lazy for i := 0; i < right-left+1; i++ { st.tree[treeIndex] = st.merge(st.tree[treeIndex], st.lazy[treeIndex]) //st.tree[treeIndex] += (right - left + 1) * st.lazy[treeIndex] // normalize current node by removing laziness } if left != right { // update lazy[] for children nodes st.lazy[leftTreeIndex] = st.merge(st.lazy[leftTreeIndex], st.lazy[treeIndex]) st.lazy[rightTreeIndex] = st.merge(st.lazy[rightTreeIndex], st.lazy[treeIndex]) // st.lazy[leftTreeIndex] += st.lazy[treeIndex] // st.lazy[rightTreeIndex] += st.lazy[treeIndex] } st.lazy[treeIndex] = 0 // current node processed. No longer lazy } if left > right || left > updateRight || right < updateLeft { return // out of range. escape. } if updateLeft <= left && right <= updateRight { // segment is fully within update range for i := 0; i < right-left+1; i++ { st.tree[treeIndex] = st.merge(st.tree[treeIndex], val) //st.tree[treeIndex] += (right - left + 1) * val // update segment } if left != right { // update lazy[] for children st.lazy[leftTreeIndex] = st.merge(st.lazy[leftTreeIndex], val) st.lazy[rightTreeIndex] = st.merge(st.lazy[rightTreeIndex], val) // st.lazy[leftTreeIndex] += val // st.lazy[rightTreeIndex] += val } return } st.updateLazyInTree(leftTreeIndex, left, midTreeIndex, updateLeft, updateRight, val) st.updateLazyInTree(rightTreeIndex, midTreeIndex+1, right, updateLeft, updateRight, val) // merge updates st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex]) }
Bài LeetCode liên quan: 218. The Skyline Problem、699. Falling Squares
VI. Phân tích độ phức tạp (Complexity Analysis)
Xét quá trình xây dựng: ta “chạm” tới mỗi lá (tương ứng mỗi phần tử của arr[]), nên tổng số nốt xử lý xấp xỉ . Do đó, thời gian xây dựng là .
Với cập nhật dạng đệ quy, mỗi bước ta loại bỏ khoảng một nửa đoạn đang xét để đi tới lá, tương tự tìm kiếm nhị phân (binary search) nên tốn . Sau khi cập nhật lá, ta cập nhật các nốt tổ tiên dọc theo đường đi lên gốc, số lượng tỷ lệ với chiều cao cây.
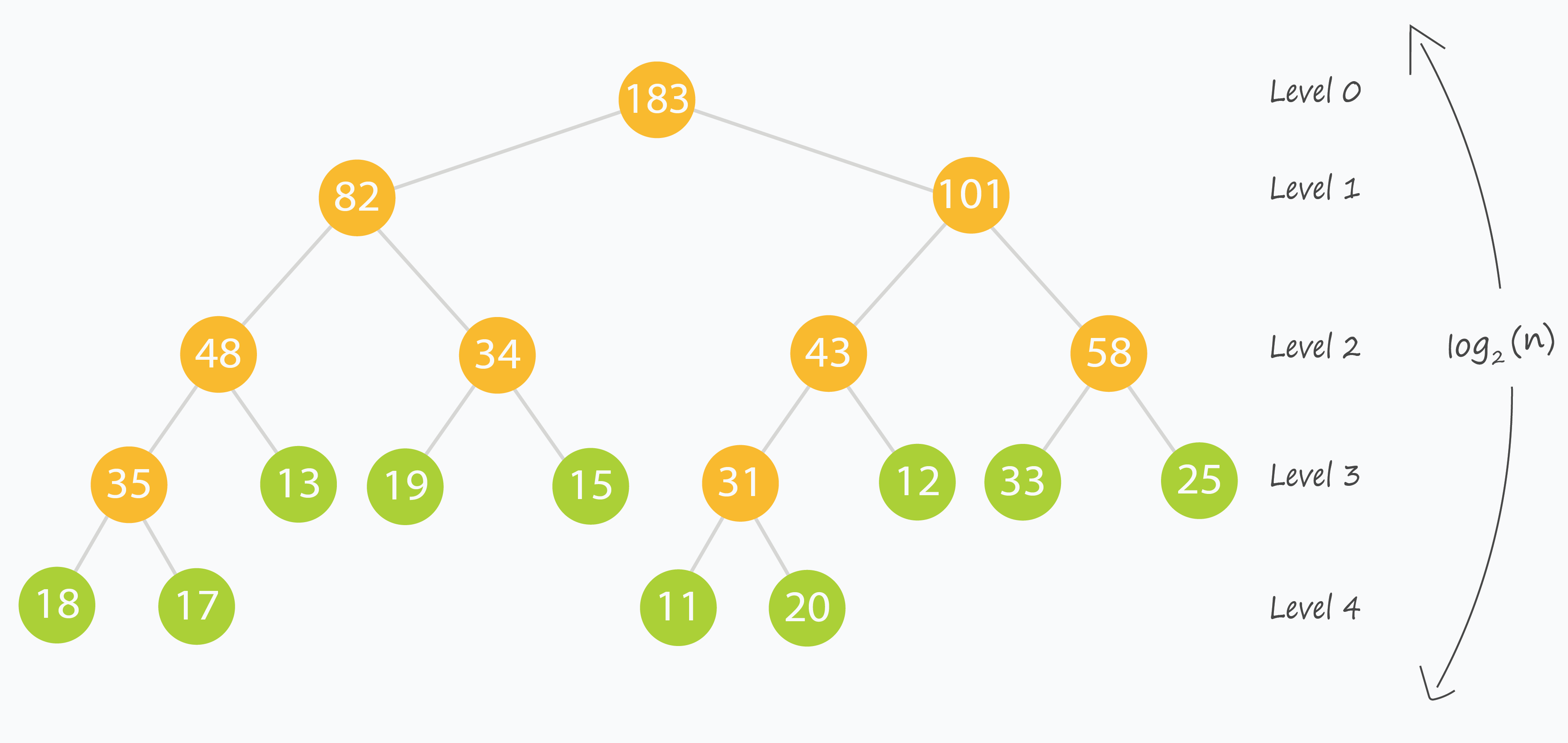
Mốc nốt giúp đảm bảo ta có đủ chỗ để biểu diễn dạng “gần như” cây nhị phân đầy đủ (complete binary tree), nên chiều cao xấp xỉ . Vì vậy, cả truy vấn và cập nhật thường có độ phức tạp .
VII. Dạng bài thường gặp
1. Truy vấn tổng đoạn (Range Sum Queries)
Range Sum Queries là một nhánh con của Range Queries. Ta có một mảng/chuỗi dữ liệu và cần xử lý các truy vấn đọc (read query) và cập nhật (update query) trên một đoạn chỉ số. Cả cây đoạn (Segment Tree) và cây Fenwick / BIT (Binary Indexed Tree, còn gọi là Fenwick Tree) đều giải dạng này rất nhanh.
Bài toán Range Sum Query tập trung vào việc truy vấn tổng các phần tử trong một đoạn. Nó có nhiều biến thể: dữ liệu bất biến (immutable), dữ liệu thay đổi được (mutable), nhiều lần cập nhật - một lần truy vấn, và nhiều lần cập nhật - nhiều lần truy vấn (2D).
2. Cập nhật một điểm (Point Update)
- HDU 1166 敌兵布阵 update: tăng/giảm tại 1 điểm (point increment/decrement) · query: tính tổng đoạn (range sum)
- HDU 1754 I Hate It update: thay thế tại 1 điểm (point assignment) · query: giá trị lớn nhất/nhỏ nhất trên đoạn (range min/max)
- HDU 1394 Minimum Inversion Number update: tăng/giảm tại 1 điểm (point increment/decrement) · query: tính tổng đoạn (range sum)
- HDU 2795 Billboard query: tìm vị trí có giá trị lớn nhất trong đoạn (arg max) (gộp thao tác update vào query)
3. Cập nhật đoạn (Range Update)
- HDU 1698 Just a Hook update: thay thế theo đoạn (range assignment) (vì chỉ query 1 lần trên toàn đoạn nên có thể in luôn thông tin nốt gốc)
- POJ 3468 A Simple Problem with Integers update: tăng/giảm theo đoạn (range add) · query: tổng đoạn (range sum)
- POJ 2528 Mayor’s posters rời rạc hoá (discretization) + update: thay thế theo đoạn (range assignment) · query: hash đơn giản
- POJ 3225 Help with Intervals update: thay thế theo đoạn + XOR theo đoạn (range xor) · query: hash đơn giản
4. Gộp đoạn (Interval Merge)
Dạng này thường hỏi đoạn liên tiếp dài nhất thỏa điều kiện trong một khoảng; vì vậy khi “đẩy lên” (push up) cần gộp thông tin của con trái và con phải.
- POJ 3667 Hotel update: thay thế theo đoạn (range assignment) · query: hỏi điểm trái nhất thỏa điều kiện (leftmost valid position)
5. Đường quét (Sweep Line)
Nhóm này thường cần sắp xếp các sự kiện (events), rồi dùng một đường quét (sweep line) quét từ trái qua phải. Điển hình: hợp diện tích hình chữ nhật (union area), hợp chu vi (union perimeter), v.v.
- HDU 1542 Atlantis update: tăng/giảm theo đoạn (range add) · query: lấy trực tiếp giá trị ở nốt gốc
- HDU 1828 Picture update: tăng/giảm theo đoạn (range add) · query: lấy trực tiếp giá trị ở nốt gốc
6. Bài toán đếm (Counting Problems)
Trên LeetCode có một nhóm bài liên quan tới đếm (counting), như 315. Count of Smaller Numbers After Self, 327. Count of Range Sum, 493. Reverse Pairs. Các bài này có thể giải theo “khuôn” sau: mỗi nốt của cây đoạn lưu số lượng (count) trong một đoạn giá trị.
// SegmentCountTree - cây đoạn dùng để đếm (counting segment tree) type SegmentCountTree struct { data, tree []int left, right int merge func(i, j int) int } // Init func (st *SegmentCountTree) Init(nums []int, oper func(i, j int) int) { st.merge = oper data, tree := make([]int, len(nums)), make([]int, 4*len(nums)) for i := 0; i < len(nums); i++ { data[i] = nums[i] } st.data, st.tree = data, tree } // Tạo cây đoạn cho đoạn [left...right] tại vị trí treeIndex func (st *SegmentCountTree) buildSegmentTree(treeIndex, left, right int) { if left == right { st.tree[treeIndex] = st.data[left] return } midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) st.buildSegmentTree(leftTreeIndex, left, midTreeIndex) st.buildSegmentTree(rightTreeIndex, midTreeIndex+1, right) st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex]) } func (st *SegmentCountTree) leftChild(index int) int { return 2*index + 1 } func (st *SegmentCountTree) rightChild(index int) int { return 2*index + 2 } // Truy vấn trên đoạn [left...right] // Query func (st *SegmentCountTree) Query(left, right int) int { if len(st.data) > 0 { return st.queryInTree(0, 0, len(st.data)-1, left, right) } return 0 } // Trong cây đoạn có gốc treeIndex (đang quản lý [left...right]), // truy vấn số lượng trong khoảng giá trị [queryLeft...queryRight] func (st *SegmentCountTree) queryInTree(treeIndex, left, right, queryLeft, queryRight int) int { if queryRight < st.data[left] || queryLeft > st.data[right] { return 0 } if queryLeft <= st.data[left] && queryRight >= st.data[right] || left == right { return st.tree[treeIndex] } midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) return st.queryInTree(rightTreeIndex, midTreeIndex+1, right, queryLeft, queryRight) + st.queryInTree(leftTreeIndex, left, midTreeIndex, queryLeft, queryRight) } // Cập nhật số đếm (count update) // UpdateCount func (st *SegmentCountTree) UpdateCount(val int) { if len(st.data) > 0 { st.updateCountInTree(0, 0, len(st.data)-1, val) } } // Với gốc treeIndex, tăng count cho đoạn [left...right] mà val thuộc vào func (st *SegmentCountTree) updateCountInTree(treeIndex, left, right, val int) { if val >= st.data[left] && val <= st.data[right] { st.tree[treeIndex]++ if left == right { return } midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex) st.updateCountInTree(rightTreeIndex, midTreeIndex+1, right, val) st.updateCountInTree(leftTreeIndex, left, midTreeIndex, val) } }