3.5 Cây Fenwick (Binary Indexed Tree)
Cây Fenwick hay còn gọi là cây chỉ số nhị phân (Binary Indexed Tree, viết tắt BIT) được đặt theo tên người phát minh Peter M. Fenwick. Năm 1994, ông công bố cấu trúc này trong bài A New Data Structure for Cumulative Frequency Tables trên tạp chí Software—Practice and Experience.
Mục tiêu ban đầu của BIT là giải bài toán tính tần suất tích luỹ (cumulative frequency) trong nén dữ liệu; còn ngày nay nó thường dùng để tính nhanh tổng tiền tố (prefix sum) và tổng đoạn (range sum). Với các bài toán theo đoạn, ngoài cây đoạn (Segment Tree) thì BIT cũng là một lựa chọn rất đáng giá. Nó có thể tính tổng tiền tố bất kỳ trong thời gian :
và hỗ trợ cập nhật động (dynamic update) tại một điểm (point update) (tăng/giảm) cũng trong . Độ phức tạp bộ nhớ là 。
Nếu dùng mảng để lưu prefix sum thì truy vấn có thể là , nhưng khi mảng bị cập nhật thường xuyên, ta phải tính lại prefix sum nhiều lần → mỗi lần. Lúc này ưu thế của BIT thể hiện ngay.
I. Khái niệm cây Fenwick 1D (1D BIT)
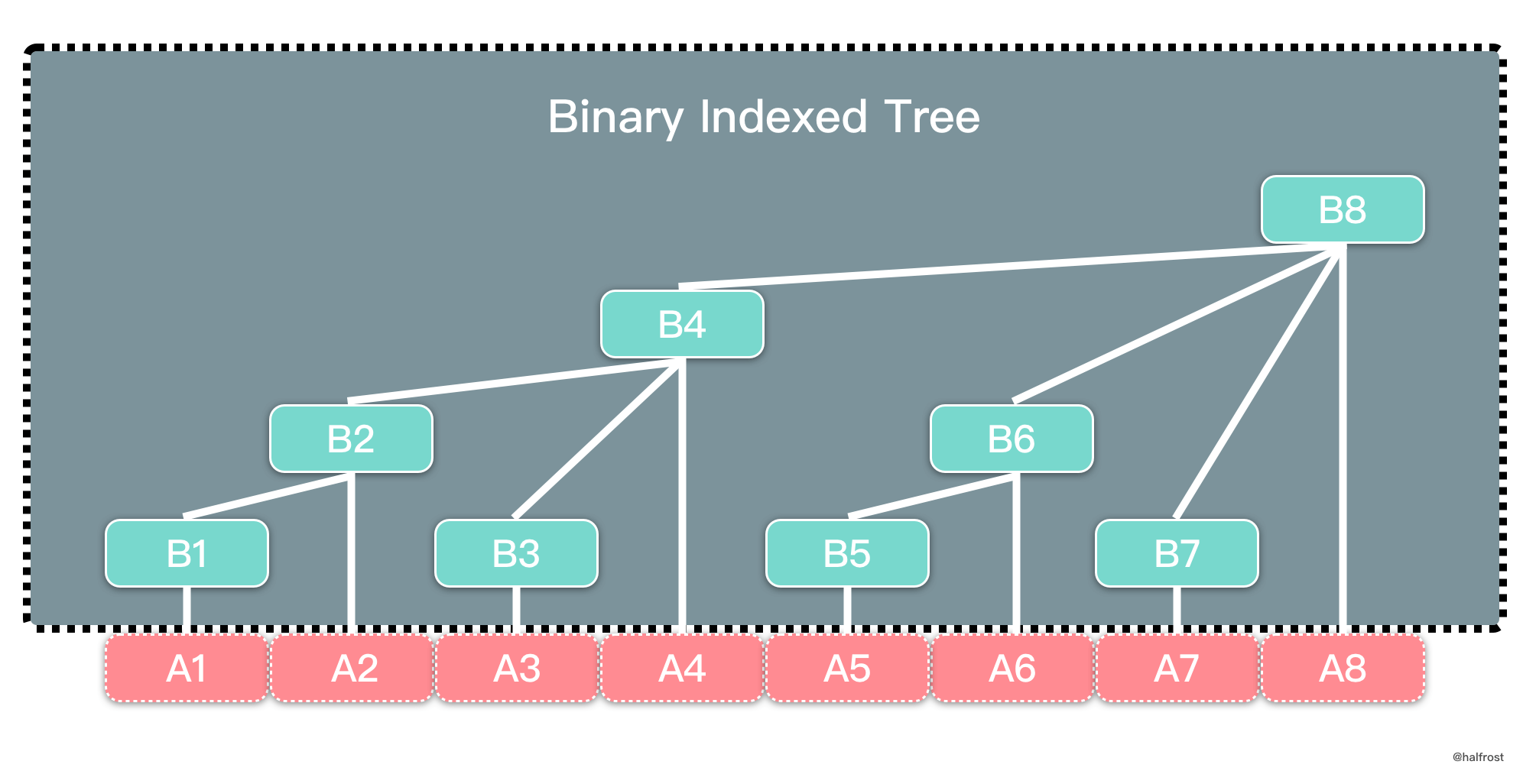
Cái tên “cây” + “mảng” có thể gây hiểu nhầm, nhưng về mặt lưu trữ vật lý (physical representation), BIT vẫn chỉ là một mảng. Điểm quan trọng là: ý nghĩa của mỗi phần tử trong mảng thể hiện quan hệ dạng cây như hình.
Trong BIT, quan hệ chỉ số cha–con thỏa:
trong đó là số lượng chữ số 0 ở cuối trong biểu diễn nhị phân (binary) của chỉ số nút con.
Ví dụ trong hình: A và B đều là mảng. A lưu dữ liệu gốc; B là mảng BIT. B4, B6, B7 là con của B8.
Vì ở dạng nhị phân là , nên → 8 là cha của 4. Tương tự, là , nên → 8 cũng là cha của 7.
1. Ý nghĩa của nút (Node meaning)
Trong BIT, các nút có chỉ số lẻ thường có thể hiểu như “lá” (leaf) — đại diện cho một điểm, và lưu đúng giá trị tại vị trí đó trong mảng gốc. Ví dụ B1, B3, B5, B7 lần lượt lưu A1, A3, A5, A7.
Các nút có chỉ số chẵn có thể xem như “nút cha” (parent) — lưu tổng trên một đoạn. Ví dụ B4 lưu .
Biên trái của đoạn là chỉ số lá “xa nhất về bên trái” thuộc nút cha đó, còn biên phải chính là chỉ số của nút. Ví dụ B8 có biên trái là B1 và biên phải là B8 nên nó biểu diễn tổng .
Có thể chứng minh bằng quy nạp rằng biên trái luôn là: trong đó là chỉ số nút (đang xét như nút cha) và là số lượng số 0 ở cuối trong biểu diễn nhị phân của . Khi đó tổng mà nút lưu là:
Code khởi tạo (init) BIT như sau:
// BinaryIndexedTree - định nghĩa BIT (Binary Indexed Tree) type BinaryIndexedTree struct { tree []int capacity int } // Init - khởi tạo func (bit *BinaryIndexedTree) Init(nums []int) { bit.tree, bit.capacity = make([]int, len(nums)+1), len(nums)+1 for i := 1; i <= len(nums); i++ { bit.tree[i] += nums[i-1] for j := i - 2; j >= i-lowbit(i); j-- { bit.tree[i] += nums[j] } } }
Hàm lowbit(i) trả về giá trị của bit 1 thấp nhất (least significant 1-bit) trong biểu diễn nhị phân của i, tức là với là số lượng số 0 ở cuối của i.
Trong hệ thống máy tính, số nguyên thường được lưu theo bù 2 (two’s complement). Nhờ bù 2, ta có thể tính lowbit(i) trong : x & -x sẽ “giữ lại” bit 1 thấp nhất. Kết quả chính là lowbit(i):
func lowbit(x int) int { return x & -x }
Nếu vẫn thấy khó hình dung, xem ví dụ: ở dạng nhị phân là (bù 2) là 。
Vậy lowbit(34) là 。
2. Thao tác cập nhật (Update / Add)
Vì quan hệ cha–con thỏa , nên khi cập nhật một điểm, ta có thể “đi lên” qua các nút tổ tiên cho tới khi vượt quá kích thước. Số nút tổ tiên tối đa là .
Thao tác Add dùng để tăng/giảm giá trị tại một chỉ số:
// Add - cộng thêm val tại index (point update) func (bit *BinaryIndexedTree) Add(index int, val int) { for index <= bit.capacity { bit.tree[index] += val index += lowbit(index) } }
3. Thao tác truy vấn (Query)
Trong BIT, truy vấn Query(i) thường là tính tổng đoạn (tổng tiền tố / prefix sum). Dựa theo ý nghĩa các nút, ta có:
Ở đây là giá trị BIT lưu tại nút . Query thực chất là một quá trình lặp/đệ quy: mỗi lần trừ đi lowbit(i) sẽ “bỏ” bit 1 thấp nhất trong biểu diễn nhị phân của i. Số lần lặp tối đa là . Code:
// Query - tính tổng tiền tố [1..index] (prefix sum) func (bit *BinaryIndexedTree) Query(index int) int { sum := 0 for index >= 1 { sum += bit.tree[index] index -= lowbit(index) } return sum }
II. BIT trong các kịch bản khác nhau
Tùy theo “thông tin” (invariant) mà mỗi nút duy trì, BIT có thể phục vụ nhiều dạng bài theo đoạn. Dưới đây bắt đầu từ bài tổng đoạn, rồi mở rộng sang các tình huống khác (ví dụ RMQ – Range Minimum/Maximum Query).
1. Tăng/giảm tại 1 điểm + tính tổng đoạn (Point update + Range sum)
Đây là kịch bản kinh điển nhất của BIT.
- Cập nhật điểm (point update): gọi
add(i, v)(tăng) hoặcadd(i, -v)(giảm). - Tính tổng đoạn $[m, n]$: dùng ý tưởng prefix sum:
query(n) - query(m-1). Trong đóquery(n)là tổng ,query(m-1)là tổng ; hiệu của chúng là tổng .
Bài LeetCode tương ứng: 307. Range Sum Query - Mutable、327. Count of Range Sum
2. Tăng/giảm theo đoạn + truy vấn 1 điểm (Range add + Point query)
Trường hợp này cần biến đổi bằng mảng hiệu (difference array). Đặt sao cho . Khi đó:
Cập nhật đoạn: tăng tất cả phần tử trong thêm thì chỉ ảnh hưởng tới 2 vị trí trong mảng hiệu:
Ta thấy không đổi; chỉ thay đổi. Vì vậy, tăng đoạn chỉ cần: add(m, v) và add(n+1, -v).
Truy vấn một điểm lúc này trở thành tính prefix sum trên mảng hiệu:
,
tức là query(n).
3. Tăng/giảm theo đoạn + tính tổng đoạn (Range add + Range sum)
Đây là phiên bản “mạnh hơn” của mục (2): vẫn dùng mảng hiệu cho cập nhật đoạn. Phần cần làm rõ là cách tính tổng đoạn.
Trước hết xét tổng :
Trong đó 。
Vì vậy để tính tổng đoạn, ta chỉ cần xây dựng thêm một BIT nữa cho dãy .
Tổng quát hơn cho đoạn :
Đến đây bài toán truy vấn tổng đoạn trong bối cảnh cập nhật đoạn đã được giải.
4. Tăng/giảm tại 1 điểm + cực trị trên đoạn (Point update + Range max/min)
Segment Tree có thể đổi phép gộp từ sum sang max/min để lấy cực trị trên đoạn mà độ phức tạp vẫn giữ .
Vậy BIT có làm được không? Câu trả lời là có, nhưng độ phức tạp thường kém hơn một chút.
Với segment tree: tính tổng đoạn là tính trên các đoạn con rồi “đẩy lên” (push up). Nếu thay sum bằng max thì ý nghĩa tương tự: lấy max của các đoạn con và push up.
Với BIT: khi tính sum, cập nhật điểm sẽ lan tới các đoạn cố định . Nhưng nếu thay sum bằng max thì ý nghĩa thay đổi: “độ tăng” tại một điểm không còn cộng dồn trực tiếp vào max của đoạn.
Làm brute-force sẽ rất chậm. Quan sát cấu trúc BIT, ta có thể tránh duyệt mọi phần tử. Nếu cập nhật , các chỉ số BIT bị ảnh hưởng có dạng:
với . Số lần cập nhật ngoài cùng giảm về . Tuy nhiên, bên trong mỗi bước vẫn cần so sánh lại trong phạm vi , nên tổng là 。
func (bit *BinaryIndexedTree) Add(index int, val int) { for index <= bit.capacity { bit.tree[index] = val for i := 1; i < lowbit(index); i = i << 1 { bit.tree[index] = max(bit.tree[index], bit.tree[index-i]) } index += lowbit(index) } }
Trên đây là cập nhật điểm. Giờ xét truy vấn cực trị trên đoạn. Segment tree chia đoạn theo kiểu chia đôi đều; còn BIT chia “không đều”. Trong BIT, biểu diễn đoạn nên tạo ra các “đoạn không đều”.
Để lấy cực trị trên bằng BIT:
- Nếu thì
- Nếu thì
func (bit *BinaryIndexedTree) Query(m, n int) int { res := 0 for n >= m { res = max(nums[n], res) n-- for ; n-lowbit(n) >= m; n -= lowbit(n) { res = max(bit.tree[n], res) } } return res }
n sẽ giảm dần và số bước tối đa cỡ cho tới khi n < m. Độ phức tạp là 。
Ví dụ kinh điển cho dạng này: HDU 1754 “I Hate It”:
Problem Description
Nhiều trường có một “truyền thống” khá khó chịu: giáo viên hay hỏi “từ bạn A tới bạn B thì ai có điểm cao nhất?”. Dù bạn có thích hay không, nhiệm vụ của bạn là viết chương trình mô phỏng các truy vấn đó. Tất nhiên đôi lúc giáo viên cũng cập nhật điểm của một học sinh.
Input
Bài gồm nhiều test, xử lý tới EOF.
Mỗi test: dòng đầu có 2 số nguyên dương N và M (0 < N <= 200000, 0 < M < 5000) lần lượt là số học sinh và số thao tác. ID học sinh từ 1..N.
Dòng 2 có N số nguyên là điểm ban đầu; số thứ i là điểm của học sinh ID=i.
Tiếp theo có M dòng, mỗi dòng gồm một ký tự C (chỉ 'Q' hoặc 'U') và hai số A, B:
- Nếu C = 'Q': truy vấn điểm cao nhất trong đoạn ID [A, B] (bao gồm A, B).
- Nếu C = 'U': cập nhật điểm của học sinh ID=A thành B.
Output
Với mỗi truy vấn 'Q', in ra điểm cao nhất trên một dòng.
Sample Input
5 6
1 2 3 4 5
Q 1 5
U 3 6
Q 3 4
Q 4 5
U 2 9
Q 1 5
Sample Output
5
6
5
9
Đọc đề là nhận ra ngay: cập nhật điểm + truy vấn max trên đoạn. Có thể viết code theo ý tưởng trên:
Vì OJ không hỗ trợ Go nên phần này dùng C. Một hint nhỏ: với input rất lớn,
scanf()thường nhanh hơncin.
#include <iostream> #include <stdio.h> #include <stdlib.h> using namespace std; const int MAXN = 3e5; int a[MAXN], h[MAXN]; int n, m; int lowbit(int x) { return x & (-x); } void updata(int x) { int lx, i; while (x <= n) { h[x] = a[x]; lx = lowbit(x); for (i=1; i<lx; i<<=1) h[x] = max(h[x], h[x-i]); x += lowbit(x); } } int query(int x, int y) { int ans = 0; while (y >= x) { ans = max(a[y], ans); y --; for (; y-lowbit(y) >= x; y -= lowbit(y)) ans = max(h[y], ans); } return ans; } int main() { int i, j, x, y, ans; char c; while (scanf("%d%d",&n,&m)!=EOF) { for (i=1; i<=n; i++) h[i] = 0; for (i=1; i<=n; i++) { scanf("%d",&a[i]); updata(i); } for (i=1; i<=m; i++) { scanf("%c",&c); scanf("%c",&c); if (c == 'Q') { scanf("%d%d",&x,&y); ans = query(x, y); printf("%d\n",ans); } else if (c == 'U') { scanf("%d%d",&x,&y); a[x] = y; updata(x); } } } return 0; }
Đoạn code trên đã AC. Nếu hứng thú bạn có thể tự làm lại bài ACM này.
5. Chồng đoạn + cực trị tại điểm (Range overlay + Point max)
Đến đây có thể bạn sẽ thắc mắc: dạng này chẳng phải giống “tăng/giảm đoạn + truy vấn điểm” ở mục (2) sao? Có thể áp dụng ý tưởng tương tự, nhưng rắc rối nằm ở chỗ: sau khi chồng nhiều đoạn, cập nhật tại mỗi điểm không còn là “delta” đơn giản, mà ta phải tự duy trì một cực trị (max).
Ví dụ, đoạn đang có giá trị 7, rồi đoạn tăng thêm 2. Cách đúng là: tăng 2, tăng 2, còn giữ nguyên vì . Đó mới chỉ là chồng 2 đoạn; chồng càng nhiều đoạn thì việc “tách đoạn” càng phức tạp. Lúc này nhiều người sẽ nghĩ tới segment tree — đúng là rất mạnh cho dạng này — nhưng ở đây chỉ bàn về BIT.
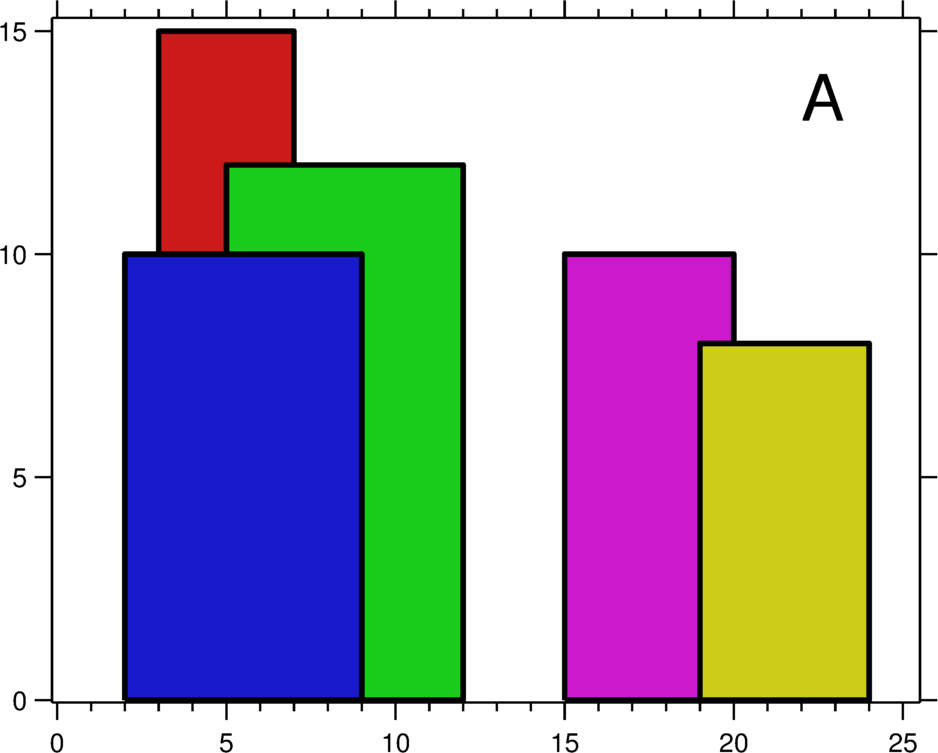
Tại thời điểm tác giả viết, LeetCode có 1836 bài và tag Binary Indexed Tree chỉ có 7 bài; trong đó 218. The Skyline Problem được xem là “khó” nhất. Bài skyline thuộc dạng chồng đoạn + cực trị theo điểm. Tác giả dùng bài này để minh hoạ cách làm thường gặp.
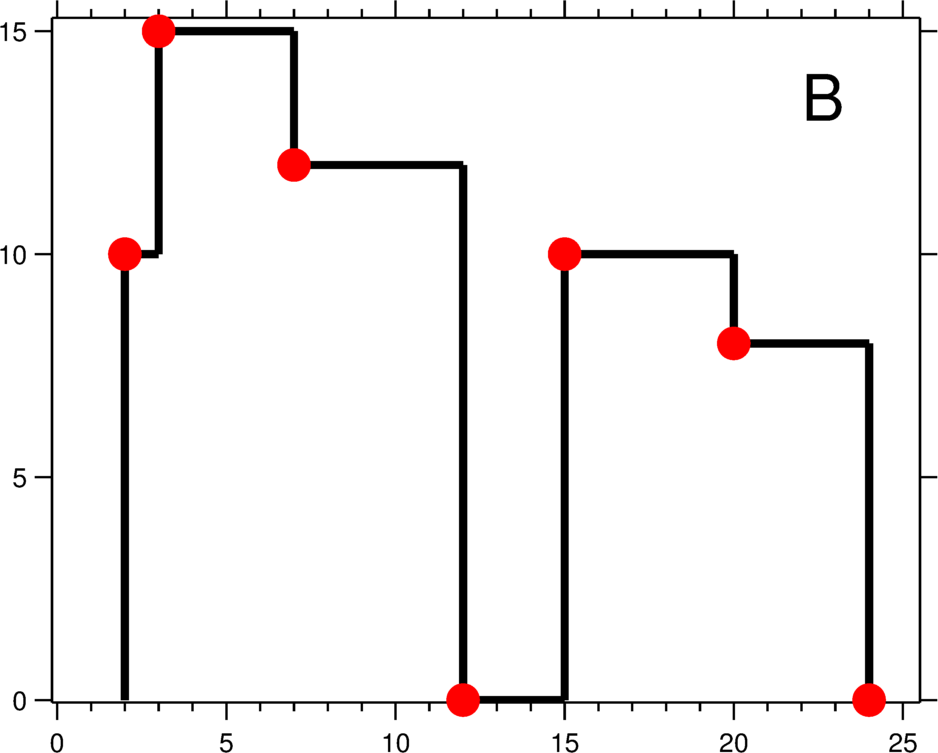
Bài toán skyline thực chất là tìm “đường bao” của các đoạn chồng nhau, nói nôm na là duy trì cực trị (max) trên từng đoạn. Có 2 vấn đề chính:
- Duy trì cực trị (max): khi một toà nhà cao kết thúc, các toà nhà còn lại vẫn phải chọn ra giá trị lớn nhất làm skyline. Nhiều đoạn chồng chéo khiến việc duy trì max trở thành điểm then chốt.
- Duy trì các điểm gãy (turning points): có những toà nhà chỉ chồng một phần, khiến skyline xuất hiện điểm gãy (điểm đỏ trong hình). BIT xử lý các điểm này như thế nào?
Giải vấn đề (1) trước (duy trì cực trị). BIT cơ bản chỉ có 2 thao tác Add() và Query(). Theo cách giải thích ở trên, hai thao tác mặc định chưa đáp ứng trực tiếp yêu cầu skyline. Ta có thể sửa Add() để duy trì max() trên một đoạn. Nhưng max() thì dễ lấy, lại rất khó “gỡ bỏ” khi một toà nhà kết thúc.
Ví dụ trên hình: đoạn có max 15. Theo định nghĩa BIT, đoạn vẫn có max 15, nhưng thực tế max chỉ là 12. Làm sao duy trì đúng?
Vì max khó “gỡ”, ta đổi góc nhìn: thay vì prefix query , ta đổi Query(i) sang ý nghĩa hậu tố (suffix):
.
Khi đó, với max trên đoạn là , thì Query(j+1) sẽ không chứa max của vì nó truy vấn . Cách đổi này giúp tránh ảnh hưởng “tích luỹ max” của các toà nhà trước lên các đoạn sau.
Cụ thể: rời rạc hoá và sắp xếp các điểm theo trục tăng dần, rồi duyệt từ trái sang phải. Add() khi gặp cạnh trái sẽ “đưa” chiều cao vào vị trí cạnh phải (đại diện cho suffix), để suffix query lấy max đúng. Nhờ vậy ta không cần xử lý “gỡ” max.
Có thể duyệt từ phải sang trái và giữ prefix query không? Có thể, và giải được vấn đề (1). Nhưng để giải vấn đề (2) (điểm gãy/turning points) thì cách đó sẽ khó hơn.
Giải vấn đề (2): nếu dùng prefix query, tại điểm ta phải xét cả các đoạn kết thúc ở lẫn các đoạn bắt đầu ở , dễ rối. Nếu dùng suffix query thì tránh được điều này: truy vấn không cần xét các đoạn “kết thúc tại i”. Code BIT cho bài này như sau:
const LEFTSIDE = 1 const RIGHTSIDE = 2 type Point struct { xAxis int side int index int } func getSkyline3(buildings [][]int) [][]int { res := [][]int{} if len(buildings) == 0 { return res } allPoints, bit := make([]Point, 0), BinaryIndexedTree{} // [x-axis (value), [1 (left) | 2 (right)], index (building number)] for i, b := range buildings { allPoints = append(allPoints, Point{xAxis: b[0], side: LEFTSIDE, index: i}) allPoints = append(allPoints, Point{xAxis: b[1], side: RIGHTSIDE, index: i}) } sort.Slice(allPoints, func(i, j int) bool { if allPoints[i].xAxis == allPoints[j].xAxis { return allPoints[i].side < allPoints[j].side } return allPoints[i].xAxis < allPoints[j].xAxis }) bit.Init(len(allPoints)) kth := make(map[Point]int) for i := 0; i < len(allPoints); i++ { kth[allPoints[i]] = i } for i := 0; i < len(allPoints); i++ { pt := allPoints[i] if pt.side == LEFTSIDE { bit.Add(kth[Point{xAxis: buildings[pt.index][1], side: RIGHTSIDE, index: pt.index}], buildings[pt.index][2]) } currHeight := bit.Query(kth[pt] + 1) if len(res) == 0 || res[len(res)-1][1] != currHeight { if len(res) > 0 && res[len(res)-1][0] == pt.xAxis { res[len(res)-1][1] = currHeight } else { res = append(res, []int{pt.xAxis, currHeight}) } } } return res } type BinaryIndexedTree struct { tree []int capacity int } // Init - khởi tạo BIT func (bit *BinaryIndexedTree) Init(capacity int) { bit.tree, bit.capacity = make([]int, capacity+1), capacity } // Add - cập nhật theo hướng hậu tố (suffix max) func (bit *BinaryIndexedTree) Add(index int, val int) { for ; index > 0; index -= index & -index { bit.tree[index] = max(bit.tree[index], val) } } // Query - truy vấn hậu tố (suffix max) func (bit *BinaryIndexedTree) Query(index int) int { sum := 0 for ; index <= bit.capacity; index += index & -index { sum = max(sum, bit.tree[index]) } return sum }
Bài này còn có thể giải bằng segment tree và sweep line. Sweep line và BIT chạy rất nhanh; segment tree thường chậm hơn một chút.
III. Ứng dụng thường gặp
Phần này nói về các ứng dụng phổ biến của BIT.
1. Đếm nghịch thế (Inversion count)
Cho một hoán vị P gồm số , hãy đếm số cặp chỉ số sao cho và .
Đây là bài toán nghịch thế kinh điển. Cách ngây thơ là duyệt mọi cặp và đếm nếu → , quá chậm. BIT giúp đưa bài toán về mức .
Nếu đổi đề thành thì ý tưởng vẫn vậy, chỉ cần thêm bước rời rạc hoá (discretization) ở đầu.
Giả sử cần rời rạc hoá (discretization). Ta ánh xạ các giá trị về dải 1..n theo thứ tự tăng dần: giá trị trùng nhau nhận cùng hạng; các hạng bị thiếu được “nén” lại liên tục. Kết quả là một mảng B có phần tử thuộc {1,2,...,n} nhưng vẫn theo thứ tự lộn xộn như mảng gốc.
Ví dụ mảng gốc int[9,8,5,4,6,2,3,8,7,0] có số 8 lặp và thiếu 1; ánh xạ về [1,9] ta được int[9,8,5,4,6,2,3,8,7,1].
Tiếp theo tạo một BIT để lưu mảng C (chỉ số từ 1): nếu giá trị i đã xuất hiện thì C[i]=1, ngược lại C[i]=0. Ban đầu mọi C[i]=0. Duyệt B từ trái qua phải:
- Gọi
Add(B[j], 1)để đánh dấu xuất hiện. Query(B[j])cho biết có bao nhiêu phần tử đã xuất hiện.
Nếu đã chèn tổng cộng phần tử, thì chính là số phần tử lớn hơn B[j] (tạo nghịch thế với B[j]); cộng vào đáp án.
func reversePairs(nums []int) int { if len(nums) <= 1 { return 0 } arr, newPermutation, bit, res := make([]Element, len(nums)), make([]int, len(nums)), template.BinaryIndexedTree{}, 0 for i := 0; i < len(nums); i++ { arr[i].data = nums[i] arr[i].pos = i } sort.Slice(arr, func(i, j int) bool { if arr[i].data == arr[j].data { if arr[i].pos < arr[j].pos { return true } else { return false } } return arr[i].data < arr[j].data }) id := 1 newPermutation[arr[0].pos] = 1 for i := 1; i < len(arr); i++ { if arr[i].data == arr[i-1].data { newPermutation[arr[i].pos] = id } else { id++ newPermutation[arr[i].pos] = id } } bit.Init(id) for i := 0; i < len(newPermutation); i++ { bit.Add(newPermutation[i], 1) res += (i + 1) - bit.Query(newPermutation[i]) } return res }
Trong code, newPermutation chính là mảng B sau khi rời rạc hoá. Duyệt B và chèn dần vào BIT.
Ví dụ B = int[9,8,5,4,6,2,3,8,7,1], khi chèn 6 nghĩa là “6 đã xuất hiện”. query(6) cho biết số phần tử đã xuất hiện. Nếu đã chèn 5 phần tử và có phần tử , thì là số phần tử > 6 (tạo nghịch thế với 6). Đây là cách dựng BIT theo thứ tự xuôi (forward).
Một cách khác là dựng BIT theo thứ tự ngược (backward), ví dụ:
for i := len(s) - 1; i > 0; i-- { bit.Add(newPermutation[i], 1) res += bit.Query(newPermutation[i] - 1) }
Vì chèn ngược, các phần tử đã chèn luôn có chỉ số lớn hơn i. Khi ta query số phần tử nhỏ hơn hiện tại, đó chính là số nghịch thế với phần tử tại i.
Lưu ý: khi đếm nghịch thế, đừng đếm trùng. Ví dụ, nếu vừa đếm các phần tử “trước j nhưng lớn hơn B[j]”, lại vừa đếm các phần tử “sau j nhưng nhỏ hơn B[j]”, bạn sẽ tạo ra rất nhiều phép đếm lặp. Hãy thống nhất một hướng: hoặc chỉ đếm “trước mình nhưng lớn hơn”, hoặc chỉ đếm “sau mình nhưng nhỏ hơn” — không trộn lẫn.
Bài LeetCode tương ứng: 315. Count of Smaller Numbers After Self、493. Reverse Pairs、1649. Create Sorted Array through Instructions
2. Đếm nghịch thế trong một đoạn (Range inversion count)
Cho dãy và có truy vấn đoạn . Với mỗi truy vấn, hãy đếm số cặp chỉ số sao cho và .
Bài này giống bài nghịch thế cơ bản nhưng có thêm ràng buộc theo đoạn. Ràng buộc này ảnh hưởng việc chọn cặp nghịch thế. Ví dụ với dãy [1,3,5,2,1,1,8,9,8,6,5,3,7,7,2], hỏi nghịch thế trong đoạn : các phần tử ngoài đoạn (như 3 và 5 ở trước) không được tính dù chúng có lớn hơn 2.
Đầu tiên, sắp xếp các truy vấn theo đầu phải (right endpoint) tăng dần như hình:
Cũng có thể sắp xếp truy vấn theo đầu trái (left endpoint) giảm dần. Nếu làm vậy, phần xây BIT bên dưới phải chèn theo thứ tự ngược, và khi đếm sẽ tìm các cặp “chỉ số lớn hơn nhưng giá trị nhỏ hơn”. Cả hai cách đều làm được; ở đây chọn một cách để giải thích.
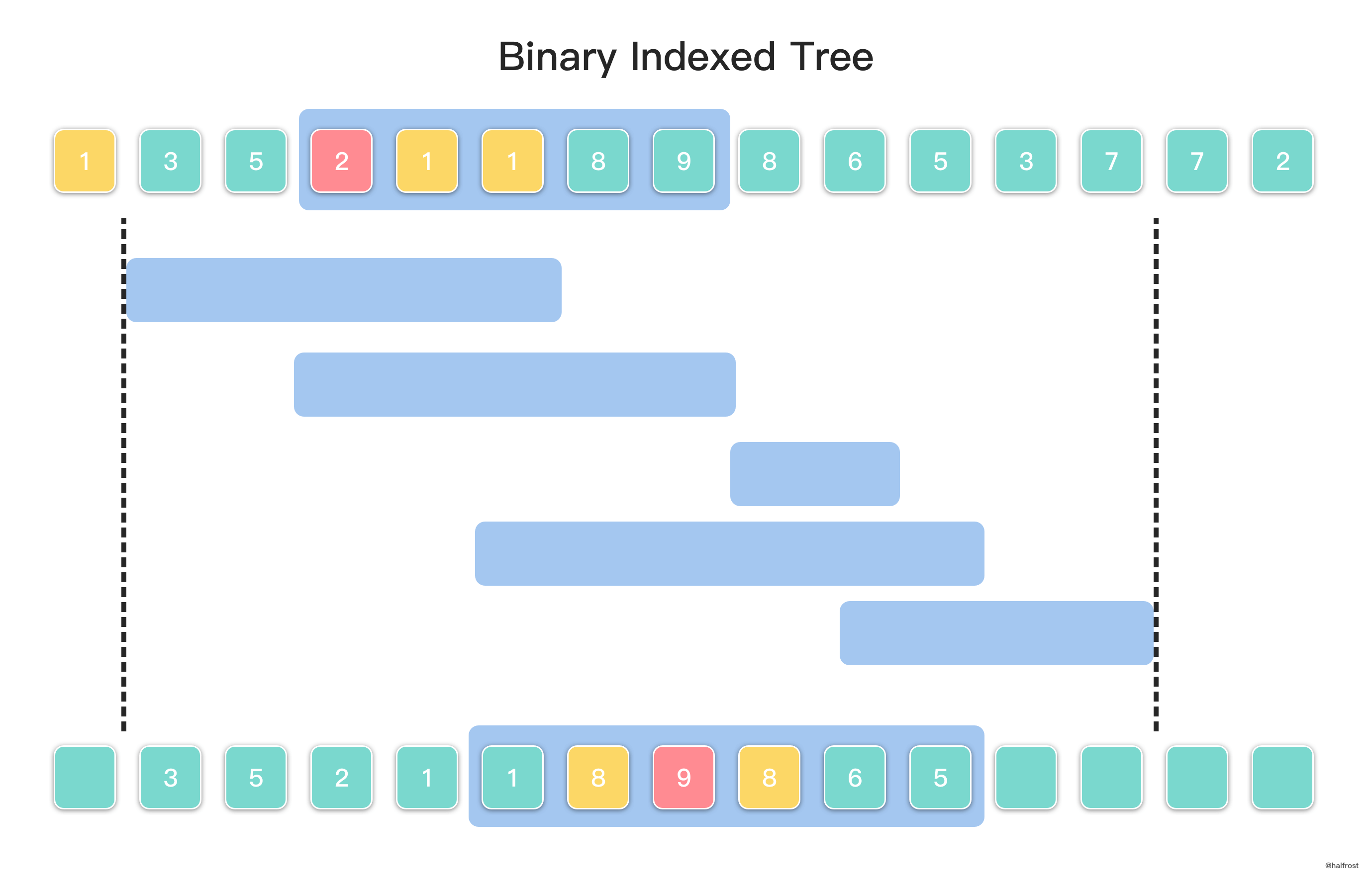
Khoảng bao phủ tổng thể quyết định phạm vi các phần tử cần đưa vào BIT. Như hình, nếu các truy vấn chỉ nằm trong thì các phần tử ở chỉ số 0, 13, 14 không cần quan tâm và cũng không cần chèn vào BIT.
Khi đếm nghịch thế theo đoạn, ta còn dùng một mảng phụ C[k]: C[k] là số lượng phần tử nhỏ hơn A[k] đã xuất hiện trước khi chèn A[k] vào BIT.
Ví dụ A[7]=9 thì C[7]=6 vì trước đó có 3,5,2,1,1,8 nhỏ hơn 9.
Vì ta chọn sắp xếp truy vấn theo đầu phải tăng dần, nên BIT cũng được xây bằng cách chèn tuần tự từ trái sang phải. Nhờ vậy, các truy vấn “trôi” từ trái qua phải sẽ lần lượt có đáp án.
Trong hình, giả sử đang xử lý truy vấn thứ 4, đoạn đó chứa các giá trị 1,8,9,8,6,5. Tại thời điểm này BIT đã chèn các phần tử trong phạm vi như hình. Khi duyệt từng phần tử trong đoạn truy vấn, Query(A[i] - 1) - C[i] chính là số nghịch thế mà chỉ số i đóng góp trong truy vấn hiện tại. Ví dụ với phần tử 9:
Vì phần tử A[i] đã được chèn vào BIT trước, nên Query() phản ánh tình trạng “toàn cục” hiện tại: số phần tử nhỏ hơn 9 trong phạm vi . Ở đây có 9 phần tử < 9, nên Query(A[i] - 1) ra 9.
Trong khi đó, C[7] là số phần tử < 9 trước khi chèn 9 vào BIT, bằng 6. Hiệu chính là số nghịch thế của 9 trong đoạn truy vấn hiện tại. Nhìn hình cũng thấy đúng: trong đoạn, các phần tử ở chỉ số lớn hơn 9 nhưng giá trị nhỏ hơn 9 có đúng 3 phần tử (8, 6, 5).
Tóm tắt:
- Rời rạc hoá mảng A[i] (nếu cần).
- Sắp xếp các truy vấn theo đầu phải tăng dần.
- Duyệt các truy vấn theo thứ tự đó; đồng thời chèn các phần tử vào BIT từ trái qua phải (đủ tới đầu phải), và tính C[i] trước khi chèn.
- Với mỗi truy vấn, duyệt các phần tử trong đoạn và cộng dồn
Query(A[i] - 1) - C[i]để ra tổng nghịch thế trong đoạn.
3. Nghịch thế trên cây (Tree inversion count)
Cho một cây có nút. Với mỗi nút, hãy đếm trong cây con (subtree) của nó có bao nhiêu nút có “nhãn/ID” nhỏ hơn nó.
Bài này có thể quy về mảng bằng cách dùng duyệt tiền tự (preorder traversal): gọi pre[i] là thứ tự của nút i trong preorder, và a[i] là số nút trong cây con của i. Khi đó, đoạn mà i quản lý trong mảng là . Sau đó có thể biến thành bài “nghịch thế theo đoạn” để giải.
IV. BIT hai chiều (2D BIT)
BIT có thể mở rộng lên 2D, 3D hoặc cao hơn. BIT hai chiều dùng để giải các bài toán thống kê trên mặt phẳng rời rạc.
// BinaryIndexedTree2D - BIT 2 chiều type BinaryIndexedTree2D struct { tree [][]int row int col int } // Add - cập nhật điểm (i, j) func (bit2 *BinaryIndexedTree2D) Add(i, j int, val int) { for i <= bit2.row { k := j for k <= bit2.col { bit2.tree[i][k] += val k += lowbit(k) } i += lowbit(i) } } // Query - truy vấn tổng tiền tố 2D func (bit2 *BinaryIndexedTree2D) Query(i, j int) int { sum := 0 for i >= 1 { k := j for k >= 1 { sum += bit2.tree[i][k] k -= lowbit(k) } i -= lowbit(i) } return sum }
Nếu BIT 1D duy trì thống kê trên trục số,
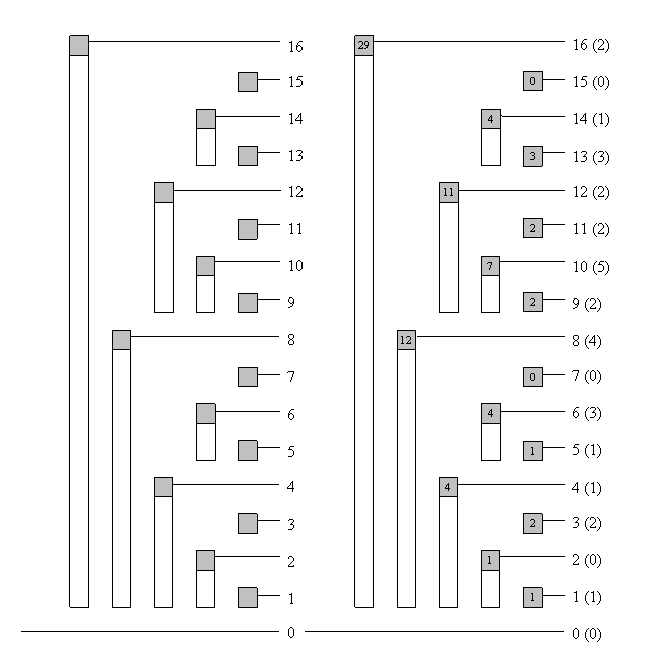
thì BIT 2D duy trì thống kê trong hệ tọa độ 2 chiều. Cả trục X và Y đều tuân theo tính chất của BIT 1D.